Anatomie d'une Transformation - 25 ans d'Évolution de l'Architecture des Données d’Entreprise (2000-2025)
Cette analyse retrace vingt-cinq ans de transformation de l’architecture des données d’entreprise à travers deux grilles de lecture complémentaires : La lecture transversale suit neuf dimensions – usages & exigences, processus, fonctions, applications, techniques, opérations, culture, gouvernance et stratégie. Elle met en évidence les trajectoires différen-ciées de chacune, les asynchronies entre leurs évolutions et les interdépendances qui structurent la trans-formation. La lecture verticale met en lumière trois ruptures temporelles, moments où plusieurs dimensions bascu-lent simultanément sous l’effet de déclencheurs précis : la spécialisation data (2005–2010), l’hybridation organisationnelle (2012–2018) et l’avènement des architectures data-natives (2018–2025). L’articulation de ces deux grilles de lecture révèle que la mutation ne s’est pas opérée de manière linéaire, mais par vagues successives. Elle permet de comprendre à la fois la dynamique propre de chaque dimen-sion et les effets de système qui accélèrent ou contraignent la transformation. Cette double lecture fournit ainsi une clé de compréhension essentielle pour anticiper les tensions émergentes et orienter les straté-gies futures. Cette double lecture constitue un outil opérationnel pour les praticiens et un cadre pédagogique pour l'enseignement : Pour les dirigeants et CDO, elle offre une méthode de diagnostic de maturité organisa-tionnelle et d'anticipation des tensions émergentes, permettant d'orchestrer la transformation en tenant compte des interdépendances entre dimensions. Pour les enseignants et étudiants, elle propose une ap-proche systémique qui dépasse les visions purement techniques pour embrasser la complexité organisa-tionnelle de la transformation data et fournir un cadre d'analyse applicable à tout secteur d'activité.
Charles Ngando Black
11/11/202523 min temps de lecture


Résumé Exécutif
Cette analyse retrace vingt-cinq ans de transformation de l’architecture des données d’entreprise à travers deux grilles de lecture complémentaires :
La lecture transversale suit neuf dimensions – usages & exigences, processus, fonctions, applications, techniques, opérations, culture, gouvernance et stratégie. Elle met en évidence les trajectoires différenciées de chacune, les asynchronies entre leurs évolutions et les interdépendances qui structurent la transformation.
La lecture verticale met en lumière trois ruptures temporelles, moments où plusieurs dimensions basculent simultanément sous l’effet de déclencheurs précis : la spécialisation data (2005–2010), l’hybridation organisationnelle (2012–2018) et l’avènement des architectures data-natives (2018–2025).
L’articulation de ces deux grilles de lecture révèle que la mutation ne s’est pas opérée de manière linéaire, mais par vagues successives. Elle permet de comprendre à la fois la dynamique propre de chaque dimension et les effets de système qui accélèrent ou contraignent la transformation. Cette double lecture fournit ainsi une clé de compréhension essentielle pour anticiper les tensions émergentes et orienter les stratégies futures.
Cette double lecture constitue un outil opérationnel pour les praticiens et un cadre pédagogique pour l'enseignement : Pour les dirigeants et CDO, elle offre une méthode de diagnostic de maturité organisationnelle et d'anticipation des tensions émergentes, permettant d'orchestrer la transformation en tenant compte des interdépendances entre dimensions. Pour les enseignants et étudiants, elle propose une approche systémique qui dépasse les visions purement techniques pour embrasser la complexité organisationnelle de la transformation data et fournir un cadre d'analyse applicable à tout secteur d'activité.
Introduction
L'architecture des données a connu une transformation radicale au cours des vingt-cinq dernières années, passant d'un ensemble d'outils et de processus périphériques à un socle stratégique central pour les organisations. Cette mutation systémique ne s'est pas opérée de manière linéaire mais par vagues successives, chaque dimension évoluant selon sa propre temporalité tout en influençant les autres. Cette analyse s'appuie sur l'observation de tendances sectorielles convergentes et de témoignages d'acteurs de la transformation. Les projections 2020-2025 extrapolent des signaux émergents qui demeurent à confirmer par les évolutions en cours.
Lecture Transversale - Les Neuf Dimensions de la Transformation
La première grille de lecture examine l'évolution de neuf dimensions constitutives de l'écosystème data : usages et exigences, processus organisationnels, fonctions et rôles, applications, architectures techniques, modèles opérationnels, culture, gouvernance et planification stratégique.
Cette approche transversale révèle que chaque dimension suit sa propre trajectoire temporelle, créant des asynchronies qui sont autant de sources d'innovation que de tension. L'analyse granulaire de ces évolutions parallèles permet de comprendre les dynamiques d'interdépendance : comment la maturation de la gouvernance catalyse l'émergence de stratégies sophistiquées, comment l'autonomisation technique rend possible de nouveaux modèles opérationnels, comment la structuration des fonctions légitime de nouveaux processus.
Cette lecture dimension par dimension constitue le socle analytique nécessaire pour identifier, dans la section suivante, les moments de rupture où plusieurs dimensions basculent simultanément sous l'effet de déclencheurs précis.
Usages et Exigences
La transformation de l'architecture des données n'est pas d'abord le résultat d'un choix interne, mais la conséquence de pressions multiples qui, au fil du temps, ont mis sous tension le modèle binaire IT–métiers. Ces pressions se traduisent par des usages nouveaux et des exigences croissantes qui, combinés, rendent incontournable l'apparition d'un troisième pilier : la Data.
2000–2005 : Cloisonnement et Premiers Signaux
Les exigences réglementaires apparaissent dès le début des années 2000. La loi Sarbanes–Oxley (2002) impose la traçabilité des données financières, tandis que Bâle II (2004–2006) oblige les banques européennes à consolider et fiabiliser leurs reportings de risque.
Dans le secteur bancaire et financier, la mise en conformité avec Sarbanes-Oxley révèle l'incapacité des équipes à justifier rapidement l'origine des chiffres financiers. Selon une étude PwC de 2004, 78% des entreprises du Fortune 500 ont dû recruter des équipes dédiées à la traçabilité des données, avec des coûts de mise en conformité atteignant 0,06% du chiffre d'affaires en moyenne.
En grande distribution, les ERP nouvellement déployés automatisent efficacement les processus internes mais se révèlent incapables de fournir une vision client consolidée au-delà de chaque silo métier. Un même client peut être géré différemment selon qu'il achète en magasin, sur le web, ou via le service client, sans possibilité de réconciliation automatique.
2005–2010 : Tensions Réglementaires et Consolidation
Les exigences technologiques suivent le rythme des innovations : explosion du web et du e-commerce, premières mutations vers des architectures orientées services. Cette période voit naître des tensions croissantes entre la rigidité des systèmes historiques et la nécessité d'intégrer des flux de données de plus en plus hétérogènes.
Dans les banques européennes, Bâle II oblige à agréger des données de crédit, de marché et de risques opérationnels historiquement gérées par des équipes distinctes. Les rapprochements se font manuellement dans des fichiers Excel, générant des coûts opérationnels considérables et des risques d'erreur majeurs lors des arrêtés trimestriels.
En industrie, les premières tentatives de traçabilité produits, notamment dans l'alimentaire suite aux crises sanitaires, révèlent l'absence de référentiel partagé entre les équipes supply chain et qualité. Reconstituer l'historique d'un produit nécessite de solliciter manuellement plusieurs systèmes métier sans garantie de cohérence temporelle.
2010–2015 : Émergence des Rôles Data
Les exigences métier traduisent une demande d'intégration transversale : disposer d'une vision client 360°, relier les maillons de la supply chain, piloter en temps réel la performance ou anticiper les événements grâce à des modèles prédictifs.
En assurance, Solvabilité II pousse les organisations à créer des fonctions spécialisées de gestion de données de risque. L'apparition d'équipes Data Quality dédiées marque une première reconnaissance de la data comme domaine d'expertise à part entière, nécessitant des compétences spécifiques distinctes des rôles IT ou actuariels traditionnels.
Dans l'e-commerce, l'explosion des données web et mobiles génère des volumes et une variété inédits. Cela conduit à la naissance des premiers Data Labs, équipes hybrides associant data scientists, analystes métier et développeurs pour exploiter ces nouveaux flux de données comportementales dans des démarches d'optimisation en temps réel.
2015–2020 : Gouvernance Explicite et Acculturation
Les exigences sociétales et culturelles prennent de l'ampleur : attentes croissantes des clients et des citoyens en matière de transparence, montée en puissance de la confiance numérique comme facteur de compétitivité, nécessité de concilier exploitation et protection des données.
Dans le secteur public, le RGPD (2018) impose la nomination de DPO et structure des processus de protection des données personnelles. L'AFCDP recensait 25 000 DPO déclarés en France fin 2019, contre moins de 500 correspondants informatique et libertés en 2017, matérialisant la création d'une nouvelle fonction à grande échelle.
En santé, l'intégration progressive des données patients via les dossiers médicaux électroniques nécessite la formation d'équipes mixtes associant spécialistes Data, équipes IT et cliniciens. Ces équipes hybrides développent un langage commun et des processus de validation partagés, préfigurant les modèles collaboratifs généralisés dans la décennie suivante.
2020–2025 : Intégration Systémique et IA
Dans les télécoms, l'exploitation de la donnée en temps réel pour la détection de fraude et la prédiction du churn via l'IA nécessite une supervision Data intégrée capable de piloter des algorithmes en production 24h/24. Les équipes opérationnelles traditionnelles acquièrent des compétences data pour superviser des modèles prédictifs directement intégrés dans les parcours clients.
En transport et logistique, le développement de supply chains prédictives s'appuyant sur l'IoT et l'IA impose des processus data-centric, des plateformes hybrides cloud/edge et une culture partagée où chaque acteur de la chaîne comprend l'impact de la qualité de ses données sur l'ensemble du système.
Ainsi, usages et exigences ne sont pas périphériques : ils sont le véritable moteur de la transformation. En révélant les insuffisances du modèle binaire et en contraignant les organisations à démontrer, sécuriser, partager et valoriser leurs données, ils rendent nécessaire la recomposition architecturale qui place la Data au même rang que l'IT et les métiers.
Les Processus Organisationnels : Du Cloisonnement Binaire à l'Orchestration Data-Centric
Au début des années 2000, le paysage des processus data était marqué par une séparation binaire quasi-étanche entre le monde métier et l'univers IT. Les utilisateurs métier formulaient leurs besoins en langage naturel, souvent lors de réunions informelles, puis transmettaient ces demandes à des équipes techniques qui traduisaient selon leur propre compréhension. Cette logique de traduction successive générait d'inévitables distorsions : ce qui était demandé n'était jamais exactement ce qui était livré.
Le premier basculement s'est amorcé vers 2005-2007, sous la pression de besoins d'analyse de plus en plus sophistiqués. Les entreprises ont commencé à installer des passerelles ponctuelles : des business analysts capables de faire le pont entre les deux mondes, des ateliers de spécification plus structurés, des prototypages rapides pour valider la compréhension mutuelle. Ces passerelles restaient cependant des solutions d'exception, mobilisées projet par projet.
La véritable transformation s'est opérée entre 2010 et 2015, avec l'émergence d'une mutualisation transverse. Les processus data ont cessé d'être des couloirs isolés pour devenir des workflows partagés, orchestrés par des centres de compétences dédiés. Cette période a vu naître les premiers processus standardisés de gouvernance des données, les circuits de validation qualité, les procédures de mise à disposition self-service. L'innovation résidait dans cette capacité nouvellement acquise à traiter les besoins data comme un domaine d'expertise à part entière.
Depuis 2018, on assiste à une révolution plus profonde : l'émergence de processus centrés Data. La donnée n'est plus un sous-produit des processus métier, elle devient leur colonne vertébrale. Les organisations redessinent leurs workflows en partant de la donnée comme asset stratégique, intégrant dès la conception les enjeux de qualité, de traçabilité, de réutilisabilité. Cette logique data-centric transforme jusqu'à la manière de concevoir les produits et services.
L'Écosystème des Fonctions : De la Dispersion Artisanale à l'Orchestration Collaborative
En 2000, parler de "fonction data" aurait semblé incongru. Les compétences étaient éclatées : les statisticiens dans les directions marketing, les informaticiens dans les DSI, les contrôleurs de gestion dans les directions financières. Chacun manipulait "ses" données avec ses outils, selon ses propres standards. Cette dispersion créait une forme d'artisanat local, efficace dans son périmètre mais impossible à industrialiser.
L'évolution a commencé par l'émergence de premiers rôles spécialisés, autour de 2006-2008. Les data analysts ont été les premiers à cristalliser cette spécialisation, suivis par les responsables qualité des données. Ces fonctions restaient souvent rattachées aux directions métier ou IT traditionnelles, mais elles commençaient à développer un langage commun, des méthodes partagées, une identité professionnelle distincte.
Le tournant décisif s'est joué entre 2012 et 2016 avec l'émergence d'un écosystème de fonctions de direction spécialisées. Les Chief Data Officer ont certes joué un rôle visible, mais ils n'étaient qu'une pièce d'un puzzle plus complexe. Simultanément, les Chief Analytics Officers développaient leurs propres domaines d'expertise, les Chief Information Security Officers structuraient les enjeux de sécurité des données, et l'arrivée du RGPD a consacré les Data Protection Officers comme acteurs incontournables de la gouvernance data. Cette période a révélé la nécessité d'orchestrer ces fonctions plutôt que de les centraliser sous une autorité unique.
Aujourd'hui, on observe l'émergence d'un écosystème de fonctions data interdépendantes et matures. Chaque fonction développe ses propres processus spécialisés : le DPO structure les workflows de conformité RGPD, le CISO déploie ses propres outils de classification et de protection des données, le CAO pilote ses plateformes d'analytics. L'innovation réside dans leur capacité croissante à orchestrer des processus transverses : gouvernance partagée des référentiels, circuits de validation croisés, comités de pilotage multifonctions. Cette maturation collaborative transforme la "data literacy" d'une compétence technique en une compétence organisationnelle distribuée.
L'Évolution Applicative : Des Solutions Artisanales aux Écosystèmes Intégrés
L'histoire des applications data commence par une prolifération de solutions ad hoc. Chaque direction, chaque équipe projet développait ses propres outils : extractions Excel personnalisées, requêtes SQL artisanales, tableaux de bord construits avec les moyens du bord. Cette logique du "local" était paradoxalement très créative, mais elle générait une complexité ingérable et des risques de cohérence majeurs.
La première vague d'industrialisation, vers 2005-2009, s'est concentrée sur les contrôles. Les entreprises ont commencé à déployer des solutions de data quality, des référentiels de données, des outils d'ETL standardisés. L'objectif était de sécuriser et fiabiliser l'existant plutôt que de le transformer. Cette approche "contrôle" a permis de gagner en robustesse mais restait dans une logique défensive.
Le basculement vers la co-construction multi-domaines s'est opéré entre 2012 et 2017. Les applications data ont cessé d'être conçues en silo pour devenir des projets transverses, impliquant dès la conception les différents métiers utilisateurs. Cette période a vu fleurir les approches agiles appliquées à la data, les ateliers de co-design, les démarches de "design thinking" pour les solutions analytiques. L'innovation résidait dans cette capacité à faire converger des besoins métier hétérogènes vers des solutions techniques cohérentes.
Depuis 2018, l'évolution s'oriente vers des plateformes intégrées qui révolutionnent l'approche même des applications data. Ces plateformes ne se contentent plus d'orchestrer des outils disparates, elles offrent des environnements unifiés où les données circulent naturellement d'un usage à l'autre. L'utilisateur métier peut explorer, analyser, modéliser et partager dans un continuum technologique fluide, sans rupture d'expérience ni perte de contexte.
Les Architectures Techniques : De l'Hégémonie IT aux Plateformes Data-Natives
En 2000, l'IT régnait en maître absolu sur l'univers technique des données. Les choix de formats, de systèmes de stockage, d'architecture étaient dictés par les contraintes et les standards informatiques. Les données étaient modelées pour s'adapter aux capacités techniques disponibles, et les utilisateurs devaient composer avec ces contraintes. Cette logique "IT-centric" garantissait la cohérence technique mais au prix d'une rigidité souvent frustrante pour les métiers.
L'émergence de briques dédiées data, vers 2007-2011, a marqué les premiers signes d'émancipation. Les solutions de business intelligence, les entrepôts de données spécialisés, les outils de visualisation ont commencé à développer leurs propres standards techniques. Cette période a vu naître une forme de "dualité technique" : les systèmes transactionnels restaient dans l'orbite IT traditionnelle, tandis que les systèmes analytiques développaient leurs propres logiques.
La rupture décisive s'est produite entre 2015 et 2018 avec la séparation claire entre plateformes IT et plateformes Data. Cette séparation ne signifiait pas un divorce, mais plutôt une spécialisation assumée. Les plateformes data ont développé leurs propres architectures cloud-native, leurs propres paradigmes de traitement distribué, leurs propres standards de sécurité. Elles ont cessé d'être des extensions des systèmes IT pour devenir des écosystèmes techniques autonomes.
Aujourd'hui, cette autonomisation technique se radicalise avec l'émergence de "data platforms" qui redéfinissent les standards de l'industrie.
Ces plateformes intègrent nativement l'intelligence artificielle, le traitement en temps réel, l'élasticité cloud. Elles dépassent les fonctions traditionnelles de stockage et restitution pour développer des capacités d'enrichissement, d'augmentation et de contextualisation en continu des données.
Cette évolution technique fondamentale transforme la donnée d'un asset passif en un capital dynamique et auto-optimisant.
Les Modèles Opérationnels : Du Curatif Réactif à l'Intelligence Prédictive
Les opérations data ont longtemps fonctionné selon une logique purement curative. Quand un problème de qualité était détecté, quand un tableau de bord affichait des incohérences, quand un utilisateur signalait une anomalie, les équipes intervenaient pour corriger après coup. Cette approche réactive, dominante jusqu'en 2008-2010, créait un climat permanent de "pompierisme" où l'urgence dictait les priorités.
La transition vers le préventif s'est amorcée avec le déploiement des premiers contrôles automatisés, vers 2010-2014. Les organisations ont commencé à instrumenter leurs chaînes de traitement avec des sondes de qualité, des alertes automatiques, des tableaux de bord de supervision. Cette logique préventive permettait d'anticiper les problèmes avant qu'ils n'impactent les utilisateurs finaux, transformant progressivement la posture opérationnelle d'une logique de réparation vers une logique de prévention.
L'étape suivante, la supervision partagée, s'est développée entre 2015 et 2019. Les opérations data ont cessé d'être l'apanage des seules équipes techniques pour devenir un enjeu partagé avec les métiers. Les data stewards, les product owners data, les utilisateurs avancés ont été progressivement associés à la surveillance opérationnelle. Cette démocratisation de la supervision a créé un maillage de vigilance beaucoup plus fin et contextualisé.
Depuis 2020, on entre dans l'ère de l'anticipation intelligente. Les systèmes opérationnels intègrent des capacités prédictives qui permettent d'anticiper les défaillances, d'optimiser les performances, d'ajuster automatiquement les paramètres.
L'intelligence artificielle appliquée aux opérations data transforme la surveillance passive en pilotage proactif. Les systèmes apprennent des patterns historiques pour prédire et prévenir les incidents avant leur survenue, réduisant selon Gartner les temps d'arrêt de 25% en moyenne dans les organisations matures.
Culture : De la Méfiance à la Responsabilité Partagée
La dimension culturelle constitue souvent la variable invisible mais déterminante de la transformation. Au départ, la donnée est traitée comme un objet purement technique : les métiers l'utilisent sans en porter la responsabilité, l'IT en détient le contrôle et une méfiance réciproque s'installe.
Progressivement, les contraintes réglementaires et les nouveaux usages imposent une acculturation minimale. Celle-ci reste longtemps fragmentée : quelques responsables qualité, analystes ou gestionnaires de risques endossent des rôles de « pionniers », sans cadre collectif.
La décennie 2010 marque un tournant avec l'institutionnalisation de programmes de sensibilisation et la montée en puissance de rôles transverses (DPO, CISO, CDO) qui rendent explicite la responsabilité partagée.
Entre 2015 et 2020, ce mouvement s'élargit : la donnée s'inscrit dans les comités, les formations et les pratiques managériales, au point de devenir une composante de la culture organisationnelle. Depuis 2020, la data literacy s'impose comme une compétence stratégique : intégrée aux référentiels, aux trajectoires RH et aux réflexes opérationnels.
Cette dynamique explique les asynchronies observées entre dimensions : une organisation peut investir massivement dans des plateformes techniques ou créer de nouvelles fonctions, mais rester bloquée si ses comportements collectifs, ses croyances implicites et ses pratiques quotidiennes n'évoluent pas au même rythme. La transformation culturelle est ainsi non seulement parallèle, mais constitutive de la transformation de l'architecture des données.
La Gouvernance des Données : De l'Anarchie Organisée aux Écosystèmes Régulés
La gouvernance des données était pratiquement inexistante au début des années 2000. Cette absence n'était pas un oubli mais une conséquence logique de la nature alors périphérique des enjeux data. Les données étaient perçues comme des sous-produits des processus métier, ne nécessitant pas de gouvernance spécifique au-delà des règles IT traditionnelles de sauvegarde et de sécurité.
La première phase de structuration, vers 2006-2010, s'est caractérisée par l'imposition de règles IT aux enjeux data. Les DSI ont étendu leurs dispositifs de gouvernance traditionnels aux problématiques de données : comités techniques, standards de sécurité, procédures de changement. Cette approche "IT-imposée" apportait de la rigueur mais restait déconnectée des enjeux métier spécifiques aux données.
Le basculement vers des comités tactiques partagés s'est opéré entre 2012 et 2017. Cette période a vu naître les premiers data committees associant représentants métier et IT autour d'enjeux concrets : définition des référentiels, arbitrage sur la qualité, priorisation des développements. Ces instances mixtes ont créé un langage commun et des processus de décision partagés, transformant la gouvernance d'un exercice technique en un enjeu stratégique.
Depuis 2018, l'évolution tend vers une gouvernance multiniveaux qui reflète la complexité croissante des enjeux data. Cette gouvernance articule des instances stratégiques (data committees de direction), tactiques (comités produits data) et opérationnelles (communautés de data stewards). Chaque niveau a ses propres responsabilités, ses propres temporalités, ses propres modalités de fonctionnement. Cette architecture multicouche permet de traiter simultanément les enjeux de vision stratégique, de pilotage opérationnel et d'exécution technique.
Plus profondément, cette gouvernance multiniveaux traduit la reconnaissance de la donnée comme un asset stratégique à part entière, nécessitant des dispositifs de pilotage aussi sophistiqués que ceux déployés pour les autres actifs critiques de l'entreprise.
La Planification Stratégique : De l'Inexistence à la Vision Data-Native
Au début des années 2000, il n'existait littéralement pas de planification stratégique dédiée aux données. Cette absence n'était pas un manque mais le reflet d'une réalité : les données étaient perçues comme un moyen, jamais comme une fin. Elles apparaissaient dans les plans stratégiques uniquement comme support aux objectifs métier, sans jamais constituer un axe stratégique autonome. Les budgets data étaient noyés dans les lignes IT ou métier, sans visibilité ni pilotage spécifique.
La première émergence d'une conscience stratégique des données s'est manifestée vers 2007-2010 avec l'intégration d'objectifs data dans les stratégies IT. Les DSI ont commencé à développer des volets "Business Intelligence" dans leurs plans pluriannuels, à budgétiser spécifiquement les projets data, à définir des roadmaps technologiques dédiées. Cette approche restait technique mais marquait une première reconnaissance de la spécificité des enjeux data dans la planification d'entreprise.
Le basculement décisif s'est opéré entre 2012 et 2017 avec l'émergence de stratégies data transverses. Les entreprises ont commencé à développer des "data strategies" qui transcendaient les silos organisationnels. Ces stratégies articulaient pour la première fois vision métier et moyens techniques autour d'objectifs data explicites : amélioration de la connaissance client, optimisation opérationnelle par la donnée, développement de nouveaux services data-driven. Cette période a vu naître les premiers CDO dont la mission première était précisément de porter cette vision stratégique transverse.
Depuis 2018, nous assistons à l'émergence de stratégies data intégrées qui placent la donnée au cœur de la transformation d'entreprise. Ces stratégies ne se contentent plus de définir des objectifs data, elles redéfinissent le business model même de l'entreprise autour de ses capacités data. La planification devient "data-native" : les nouveaux produits sont conçus comme des produits data, les processus métier sont repensés pour maximiser la valeur des données générées, les partenariats stratégiques intègrent systématiquement une dimension d'échange de données.
Cette évolution de la planification stratégique marque l'achèvement d'un cycle de transformation qui a vu les données passer du statut de sous-produit technique à celui de capital stratégique central dans la création de valeur.
Synthèse et Lecture Verticale - Les Dynamiques Systémiques de la Transformation
La richesse de l'analyse transversale permet désormais de synthétiser les dynamiques communes qui traversent l'ensemble des dimensions et d'identifier les moments de rupture systémique où la transformation s'accélère de manière globale.
Cette synthèse révèle d'abord les patterns récurrents observés dans toutes les dimensions : le passage d'approches cloisonnées vers des logiques intégrées, l'émergence progressive d'une autonomie data vis-à-vis des logiques IT traditionnelles, la montée en puissance de la collaboration et de la transversalité. Ces évolutions convergentes dessinent les contours d'une véritable révolution organisationnelle.
Au-delà de ces tendances communes, l'analyse verticale met en lumière trois ruptures temporelles où ces évolutions se cristallisent simultanément : la spécialisation data (2005-2010), l'hybridation organisationnelle (2012-2018) et l'avènement des architectures data-natives (2018-2025). Ces moments charnières correspondent à des basculements systémiques où des déclencheurs précis provoquent une recomposition globale de l'écosystème.
Cette double lecture - synthèse des patterns transversaux et identification des ruptures temporelles - constitue le socle d'une compréhension systémique de la transformation et ouvre la voie à l'analyse prospective des enjeux futurs.
Cartographie Temporelle : Vingt-cinq Ans d'Évolutions Asynchrones
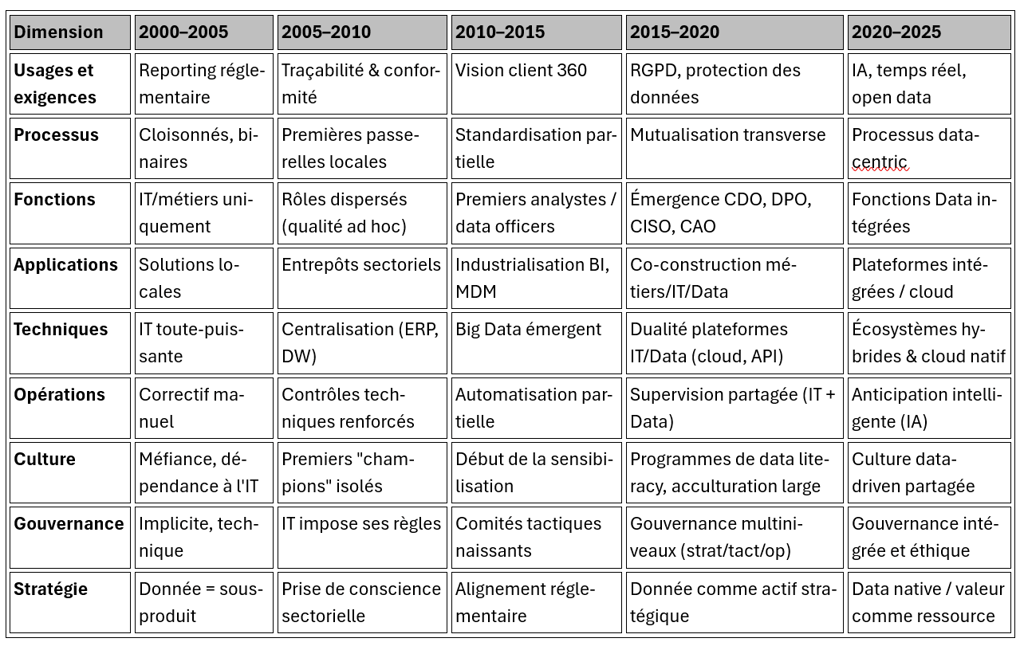
Le tableau de synthèse révèle trois dynamiques fondamentales qui structurent la transformation systémique de l'architecture des données.
Tableau de Synthèse : Les Dimensions de la Transformation
Accélération temporelle progressive
L'analyse longitudinale du tableau révèle un rythme de transformation qui s'intensifie progressivement. Les périodes 2000-2010 sont marquées par des évolutions réactives et fragmentées : reporting réglementaire sous contrainte, passerelles techniques ponctuelles, rôles dispersés sans coordination. L'accélération devient notable à partir de 2010-2015, avec une logique qui devient proactive : standardisation des processus et industrialisation BI. La période 2015-2020 confirme cette dynamique avec l'émergence de gouvernances multiniveaux et de stratégies data explicites. Enfin, 2020-2025 achève cette progression avec une maturité systémique où toutes les dimensions convergent vers l'intégration.
Asynchronies structurantes
Les décalages temporels entre dimensions révèlent des logiques d'évolution différenciées. La dimension technique évolue rapidement (ERP/DW en 2005, Big Data en 2010, dualité IT/Data en 2015), poussée par l'innovation. La dimension culturelle accuse un retard structurel (méfiance jusqu'en 2005, maturité seulement en 2020-2025) lié à la nature profonde des transformations comportementales. Les dimensions organisationnelles suivent un rythme intermédiaire, articulant innovations techniques et réalités culturelles.
Trajectoires de maturation distinctes
Chaque dimension suit sa propre logique : les usages évoluent par accumulation (chaque vague s'ajoute aux précédentes), les processus par décloisonnement progressif, la stratégie par basculement radical (de "sous-produit" à "valeur native"). Cette diversité des trajectoires explique la complexité de la transformation globale.
L'analyse de 2020-2025 révèle une convergence remarquable vers l'intégration systémique : toutes les dimensions intègrent transversalité, intelligence et éthique, témoignant d'une orchestration mature plutôt que d'une uniformisation.
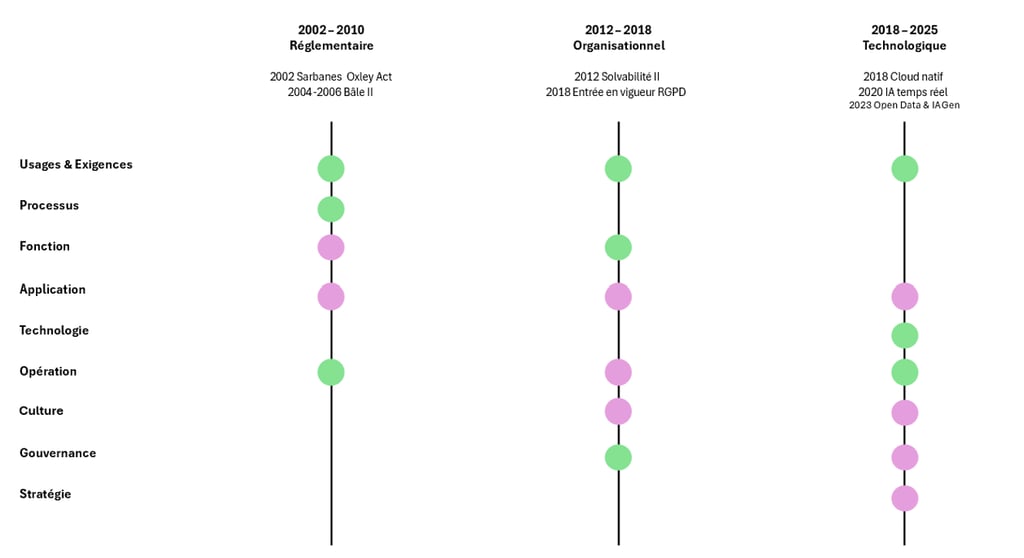
Lecture verticale : Les Ruptures systémiques
La lecture par dimensions permet de saisir les trajectoires spécifiques de chaque composante de l’architecture des données d’entreprise. Mais pour comprendre la logique d’ensemble, il faut ajouter une lecture verticale qui révèle les moments où plusieurs dimensions basculent simultanément sous l’effet de déclencheurs précis.
Ruptures temporelles et effets domino dans l’architecture des données (2002 - 2025)
Ce schéma met en évidence que la transformation de l’architecture des données ne s’explique pas seulement par l’évolution différenciée de chaque dimension, mais aussi par des ruptures transversales déclenchées par des événements précis.
2002–2010 (Réglementaire) : l’adoption de la loi Sarbanes–Oxley (2002) puis de Bâle II (2004–2006) impose de nouvelles obligations de traçabilité et de consolidation. L’impact initial se fait sentir sur les usages & exigences, les processus et les opérations. La pression se diffuse ensuite aux applications (entrepôts de données, reporting consolidé) et aux fonctions (contrôleurs qualité, premiers rôles spécialisés).
2012–2018 (Organisationnel) : avec Solvabilité II (2012) et le RGPD (adopté en 2016, appliqué en 2018), la mutation devient organisationnelle. Les fonctions (CDO, DPO) et la gouvernance sont touchées en premier. Par diffusion, la transformation gagne la culture (programmes de sensibilisation), les applications (co-construction métiers/IT), les opérations (supervision partagée) et la stratégie, où la donnée commence à être considérée comme un actif.
2018–2025 (Technologique) : l’industrialisation du cloud natif, l’essor de l’IA temps réel et l’ouverture accélérée des données (2018–2023) déclenchent une rupture technologique. Les techniques et les opérations sont les premières concernées, avant que l’onde de choc ne s’étende à la culture, à la gouvernance, à la stratégie et aux applications, redessinant l’entreprise autour d’architectures véritablement data-natives.
Ainsi, chaque rupture suit une même logique : un événement déclencheur frappe d’abord certaines dimensions, puis s’étend progressivement aux autres. La transformation ne se déploie donc pas de manière uniforme, mais par effets domino successifs qui structurent la dynamique de l’ensemble.
Conclusion : Les Dynamiques Transversales d'une Transformation Systémique
Cette analyse révèle que la transformation de l'architecture des données sur 25 ans ne relève pas d'une évolution linéaire mais d'une mutation systémique complexe. Trois ruptures majeures structurent cette évolution : l'émergence de la spécialisation (2005-2010), la constitution d'un écosystème autonome (2012-2018), et l'avènement d'approches data-natives (2018-2025).
Chaque dimension a suivi sa propre temporalité, créant parfois des décalages et des tensions. Les technologies ont évolué plus rapidement que les organisations, la stratégie a parfois précédé les moyens opérationnels, certaines fonctions ont émergé avant que les processus ne soient prêts à les accueillir. Ces asynchronies ont été autant de sources d'innovation que de complexité.
L'analyse révèle également l'importance des effets de système : l'évolution d'une dimension catalyse ou contraint l'évolution des autres. La maturation de la gouvernance permet l'émergence de stratégies sophistiquées, l'autonomisation technique rend possible de nouveaux modèles opérationnels, la structuration des fonctions légitime de nouveaux processus.
Au-delà des transformations déjà observées, cette approche granulaire permet d'identifier les tensions émergentes qui structureront probablement les évolutions futures : l'équilibre entre centralisation et décentralisation, l'articulation entre automatisation et expertise humaine, la conciliation entre performance et éthique, l'arbitrage entre standardisation et personnalisation.
La donnée a achevé sa mue d'un sous-produit technique vers un capital stratégique. Cette transformation systémique redéfinit les contours mêmes de l'entreprise data-driven et ouvre la voie à de nouveaux modèles organisationnels encore à inventer.
Vers 2025-2030 : Signaux Émergents et Trajectoires Probables
Quatre signaux émergents se dessinent aujourd'hui dans l'écosystème data et pourraient structurer la prochaine vague de transformation de l'architecture des données d'entreprise.
Convergence IA-Data industrialisée
Les plateformes cloud (AWS, Azure, GCP) ont commencé dès 2022-2023 à intégrer des services d'IA natifs dans leurs offres data. La tendance 2025-2030 pourrait voir l'industrialisation de ces capacités : augmentation automatique des données par enrichissement sémantique, génération autonome de métadonnées, correction de qualité en temps réel via des modèles d'IA. Cette évolution toucherait principalement les dimensions techniques et opérationnelles, transformant la supervision humaine vers des workflows "human-in-the-loop" où l'IA propose et l'humain valide.
Éthique et souveraineté intégrées
L'AI Act européen (2024) constitue un nouveau déclencheur externe comparable à Sarbanes-Oxley ou au RGPD. Son application progressive pourrait impacter les dimensions gouvernance (émergence de Chief AI Ethics Officers), processus (circuits de validation éthique des algorithmes) et culture (intégration de l'éthique algorithmique dans la data literacy). Cette pression réglementaire pourrait catalyser l'émergence de comités d'éthique algorithmique associant parties prenantes internes et externes.
Démocratisation technique généralisée
La convergence entre IA générative et interfaces no-code/low-code transforme radicalement l'accessibilité des analyses de données. Les utilisateurs peuvent désormais interroger leurs données en langage naturel et obtenir des visualisations ou des modèles prédictifs sans compétences techniques spécialisées. Cette tendance toucherait massivement la dimension culturelle (généralisation de la data literacy) et la dimension fonctions (transformation des rôles data vers du product management et de la supervision éthique).
Interconnexion écosystémique et marketplaces de données
Au-delà des premiers partenariats de partage de données structurés entre entreprises, émergent des infrastructures plus sophistiquées : data marketplaces internes (catalogues de données avec exposition interne), data marketplaces externes (commercialisation de datasets), et data spaces sectoriels (espaces européens de données pour la santé, l'automobile, l'agriculture). L'open data gouvernemental, initié dans les années 2010, évolue vers des écosystèmes de données ouvertes privées où les entreprises partagent sélectivement leurs données pour créer de la valeur collective. McKinsey (2024) estime que les échanges de données inter-entreprises pourraient générer 1 200 milliards de dollars de valeur supplémentaire d'ici 2030. Cette évolution impacterait la dimension stratégique (redéfinition des business models autour des échanges de données) et la dimension opérationnelle (systèmes d'anticipation et de correction automatique des défaillances atteignant des taux de résolution autonome de 90%).
Ces signaux, observés aujourd'hui à l'état émergent, s'inscrivent dans la continuité des patterns déjà identifiés : accélération de l'automatisation intelligente, montée des enjeux éthiques et réglementaires, démocratisation des usages, et intégration systémique croissante. Leur matérialisation effective dépendra de l'interaction complexe entre innovations techniques, évolutions réglementaires et transformations organisationnelles, selon la même logique systémique observée sur les vingt-cinq dernières années.
Bibliographie
AFCDP. (2020). Baromètre des DPO 2019-2020 : Deux ans après l'entrée en application du RGPD. Association Française des Correspondants à la Protection des Données à Caractère Personnel.
Chen, H., Chiang, R. H., & Storey, V. C. (2012). "Business Intelligence and Analytics: From Big Data to Big Impact." MIS Quarterly, 36(4), 1165-1188.
Davenport, T. H., & Harris, J. G. (2017). Competing on Analytics: Updated, with a New Introduction: The New Science of Winning. Harvard Business Review Press.
Deloitte. (2022). "Future of Work in Technology: Data and Analytics." Deloitte Insights.
Duhigg, C. (2016). Smarter Faster Better: The Secrets of Being Productive. Random House.
Gartner. (2023). "Market Guide for Data and Analytics Service Providers." Gartner Research.
Gartner. (2021). Market guide for AIOps platforms. Gartner Research. https://www.gartner.com/en/documents/4006681
LaValle, S., Lesser, E., Shockley, R., Hopkins, M. S., & Kruschwitz, N. (2011). "Big Data, Analytics and the Path from Insights to Value." MIT Sloan Management Review, 52(2), 21-32.
McKinsey Global Institute. (2016). The Age of Analytics: Competing in a Data-Driven World. McKinsey & Company.
MIT Technology Review. (2021). "Building a Data-Driven Organization." MIT Technology Review Insights.
Ngando Black, C. (2024). Data Office and Chief Data Officers: The Definitive Guide. Books On Demand.
PricewaterhouseCoopers. (2004). Sarbanes-Oxley compliance costs and implementation trends: Survey results. PwC Financial Services.
Redman, T. C. (2016). Getting in Front on Data: Who Does What. Harvard Business Review Press.